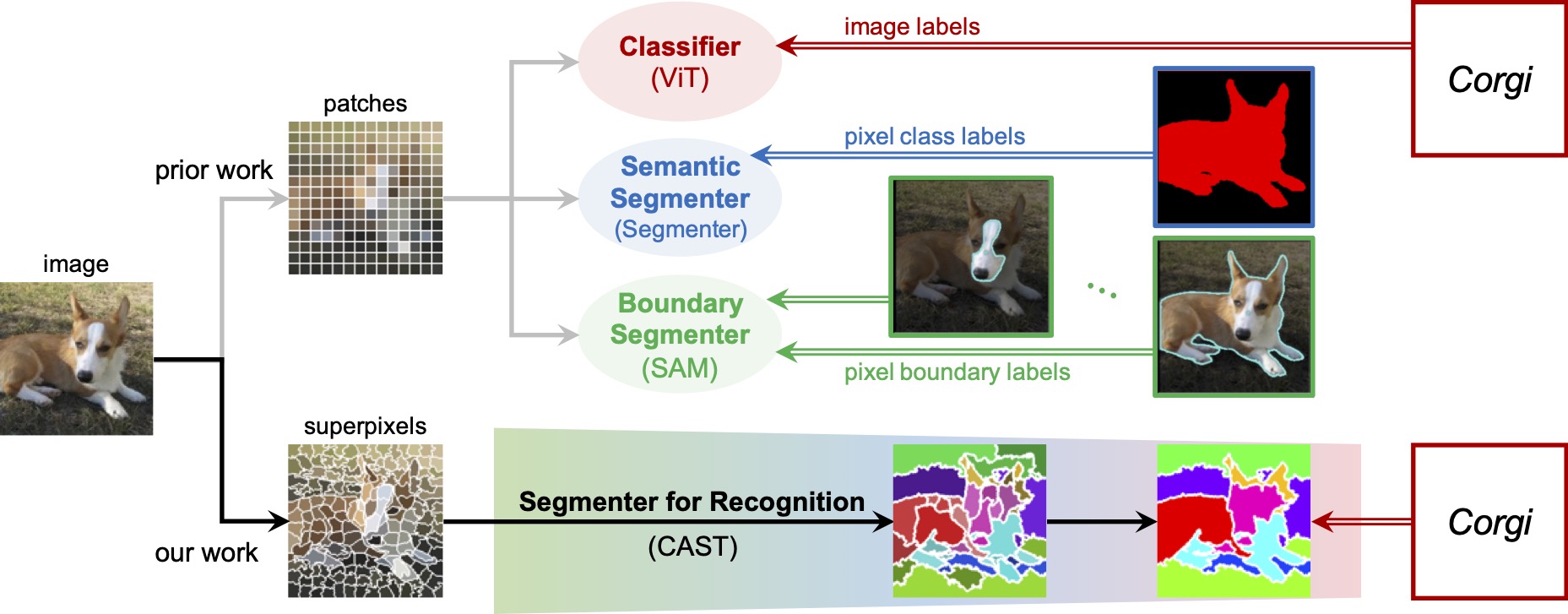
Learning Hierarchical Image Segmentation For Recognition and By Recognition
CAST
Abstract
Large vision and language models learned directly through image-text associations often lack detailed visual substantiation, whereas image segmentation tasks are treated separately from recognition, supervisedly learned without interconnections. Our key observation is that, while an image can be recognized in multiple ways, each has a consistent part-and-whole visual organization. Segmentation thus should be treated not as an end task to be mastered through supervised learning, but as an internal process that evolves with and supports the ultimate goal of recognition. We propose to integrate a hierarchical segmenter into the recognition process, train and adapt the entire model solely on image-level recognition objectives. We learn hierarchical segmentation for free alongside recognition, automatically uncovering part-to-whole relationships that not only underpin but also enhance recognition. Enhancing the Vision Transformer (ViT) with adaptive segment tokens and graph pooling, our model surpasses ViT in unsupervised part-whole discovery, semantic segmentation, image classification, and efficiency. Notably, our model (trained on unlabeled 1M ImageNet images) outperforms SAM (trained on 11M images and 1 billion masks) by absolute 8% in mIoU on PartImageNet object segmentation.
Model architecture
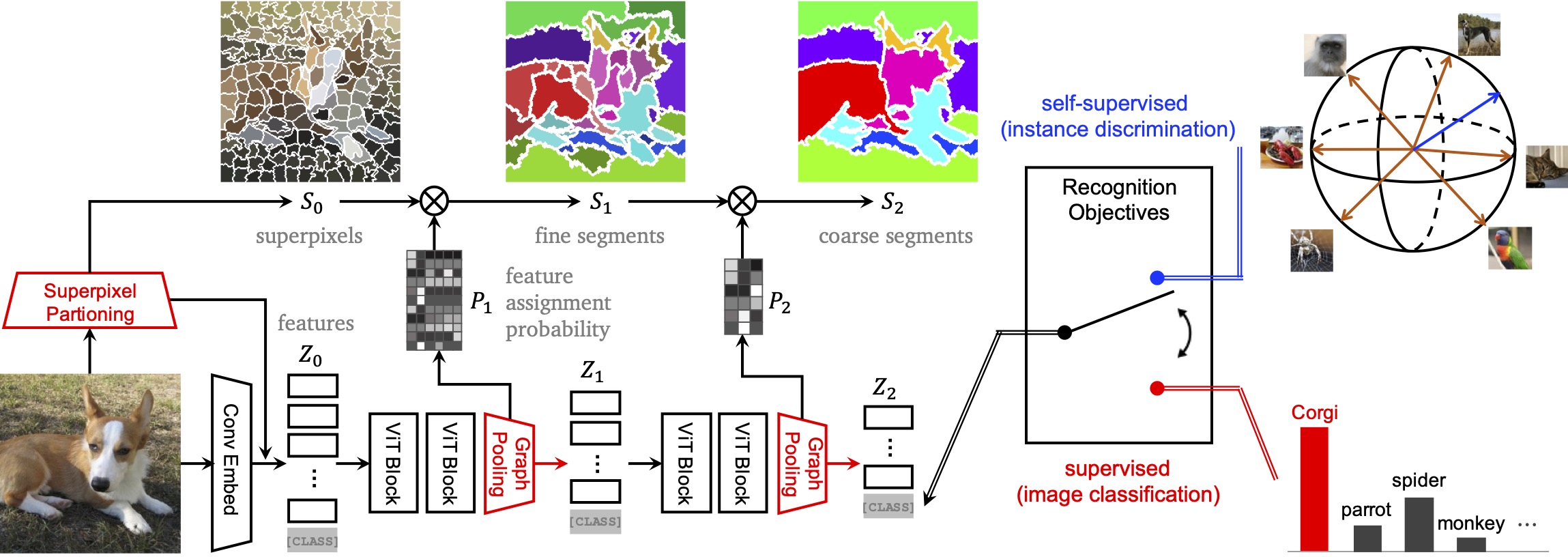
Our model implements our concept of concurrency and consistency in visual parsing by innovating ViT with adaptive segment tokens and progressive graph pooling. It starts with superpixels instead of square patches, and applies graph pooling to merge fine segments \(\mathbf S_{l-1} \) into coarse segments \(\mathbf S_{l} \). Both segment transition probability \(\mathbf P_{l} \) and segment feature \(\mathbf Z_{l} \) are learned to optimize an image-level recognition objective, which could be self-supervised instance discrimination or supervised image classification. Without any external supervision, we uncover object wholes (dog) along with small details (ears) and thin structures (legs), validating the effectiveness of our concept.
Adaptive hierarchical segmentation to improved recognition
Our model performs segmentation and recognition simultaneously during test-time adaptation. The intermediate hierarchical segmentation improves concurrently with the final image recognition, to bext explain the input image.
Discovery of parts from the whole on ImageNet
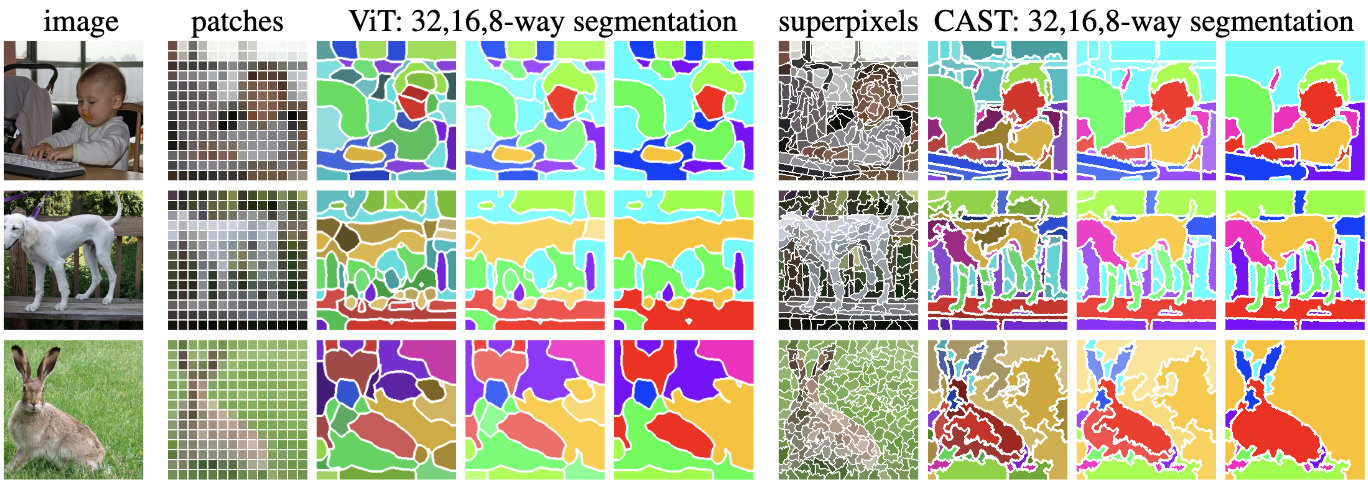
Without the need of any part annotations, our model generates high-quality hierarchical segmentation using only an image recognition objective. Our color scheme has coarse-to-fine consistency: Colors in 8-way segmentations are matched between ViT and CAST, while colors in 16(32)-way segmentations have the same hues as 8-way but vary in saturation(value) to reflect finer details. Our results more closely follow visual contours and successfully uncover entire objects with details. Our results more closely follow visual contours and successfully uncover entire objects with details like neck, thin legs, and long ears.
SOTA unsupervised hierarchical segmentation on DensePose
Training CAST and HSG on unlabeled COCO data, we evaluate 32,16,8-way segmentations on ground-truth 14,4,1-label human body parsing respectively on DensePose. We measure precision (P), recall (R), and F-score (F) on between segmentation and ground-truth human body. CAST consistently excels, especially in whole body recall.
| P R F | 14 labels | 4 labels | 1 label | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| HSG | 20.7 18.6 19.6 | 24.1 30.6 26.9 | 20.5 36.1 26.2 | |||||||
| CAST | 21.1 24.1 22.5 | 24.8 33.2 28.4 | 26.3 44.9 33.2 | |||||||

SOTA unsupervised hierarchical segmentation on PartImageNet
Training CAST on unlabeled ImageNet data, we classify 16,8-way segmentations into object and part categories with an open vocabulary classifier (OVSeg). We measure region mIoU and boundary F-score, at first object and then part levels. CAST outperforms SAM by a large margin.
| region mIoU | boundary F-score | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| model | GFLOPS | object | part | object | part | |||||
| SAM-B | 677 | 18.03 | 10.15 | 20.71 | 7.25 | |||||
| SAM-H | 3166 | 21.97 | 12.07 | 32.66 | 11.82 | |||||
| ViT | 18 | 25.34 | 11.74 | 10.92 | 4.64 | |||||
| CAST | 18 | 29.66 | 13.20 | 22.32 | 6.52 | |||||

BibTeX
@inproceedings{ke2023cast,
title={Learning Hierarchical Image Segmentation For Recognition and By Recognition},
author={Ke, Tsung-Wei and Mo, Sangwoo and Stella, X Yu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2023}
}